How to: Computerbasierte Texterkennung
I. Textdigitalisierung
Optical Character Recognition (OCR)
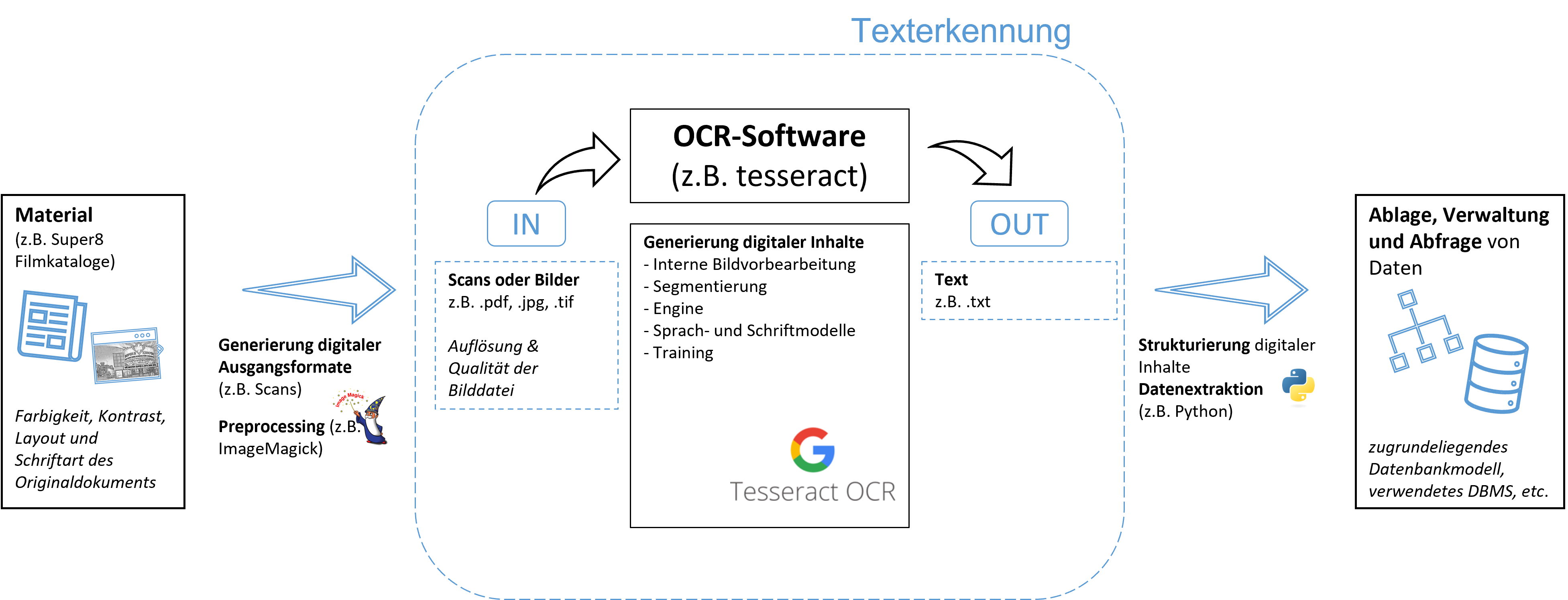
Optical Charater Recognition beschreibt den Prozess automatisierter Texterkennung innerhalb von Bilddateien (bspw. Scans). Dazu muss der zu kodierende Text zunächst als solcher erkannt und anschließend den Buchstaben Zahlenwerte zugeordnet werden. Als Ausgabe wird eine Textdatei im zuvor definierten Format erzeugt. Der Prozess der Texterkennung umfasst mehrere Arbeitsschritte und wird durch verschiedene Faktoren beeinflusst. Quelle: Möglichkeiten der Textdigitalisierung (ForText)
Stichworte: Eigenschaften von Originaldokument und Bilddatei, Umfang und Qualität des Preprocessings, Umfang und Qualität der genutzten Softwarelösung, zugrundeliegende Algorithmen)
LSTM als Grundlage der computerbasierten Texterkennung
Da die Programme gängiger Texterkennungssoftware häufig auf dem Konzept des LSTM (Long Short Term Memory) aufbauen, ist es sinnvoll, dieses zumindest im Ansatz nachvollziehen zu können:
> Denken Sie daran, wenn wir uns eine Geschichte anhören oder jemand mit uns kommuniziert. Betrachten wir jedes der Worte einzeln und verarbeiten jedes Wort unabhängig oder verbinden wir ein Wort mit dem nächsten und so weiter, um ihren Zusammenhang zu verstehen? Quelle: Einführung in das Konzept LSTM
Im Kontext des überwachten maschinellen Lernens macht sich das lange Kurzzeitgedächtnis darum die Technik der Backpropagation zunutze. Auf diese Weise vergessen die künstlichen neuronalen Einheiten (Units) Informationen nicht, wie beim herkömmlichen RNN, sondern können aufgrund eines kodierten und gewichteten Erinnerungsvermögens auf zurückliegende Informationen zugreifen und somit Lernfähigkeit und Resultate maßgeblich verbessern.
Read
- Möglichkeiten der Textdigitalisierung
- Was ist OCR?
- OCR-Software
- Einführung in RNN & LSTM
- Grundlagen LSTM
- Weiterführend: Transformer-Modelle
II. TESSERACT
Geschichte, Grundlagen und Installation
Tesseract ist eine freie Software zur Texterkennung. Ursprünglich als proprietäre Software zwischen 1984 und 1994 bei Hewlett-Packard entwickelt, wurde Tesseract 2005 bei Google aktualisiert, freigegeben und bis heute auf GitHub weiterentwickelt. Quelle: Tesseract Wikipedia
Die Texterkennungssoftware Tesseract nimmt ein Bild (in gängigen Formaten, wie bspw. .tif, .jpg, etc.) entgegen und liest den erkannten Text in eine zuvor definierte Ausgabedatei aus. Aktuelle Versionen nutzen dabei die Programmbibliothek Leptonica zur Analyse und Verarbeitung der Bilddatei. Seit Version 4.0 bietet Tesseract die Möglichkeit zur Anwendung einer auf KNN (genauer LSTM) basierenden OCR-Engine. Tesseract kann als freie Software unter den Bedingungen von Version 2.0 der Apache-Lizenz genutzt und verbreitet werden. Außerdem besteht die Möglichkeit verschiedene Formen des Trainings (für Sprachen und Schriftarten) durchzuführen. Separate Projekte stellen zwar GUIs zur Verwendung von Tesseract bereit, jedoch empfiehlt sich die Verwendung über die Kommandozeile (Beispiel). Quelle: Tesseract Wikipedia
#/media/File:Tesseractv411_light.png){kind=link}
- Hier geht es zur Installationsanleitung für alle gängigen Betriebssysteme.
- Hier gibt es ein Videotutorial von Gabriel Garcia zur manuellen Installation über GitHub.
Read
Grundlagen zur kommandozeilenbasierten Nutzung von tesseract
Die Kommandozeile nimmt Zeichenketten als Eingaben (Kommandos/ Befehle) über die Tastatur entgegen. Die Eingabe folgt einer Syntax, die meist aus einem Kommando und dazugehörigen Parametern besteht. Quelle: Kommandozeile Wikipedia
Basissyntax tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmentationmode] [-c configfiles...]
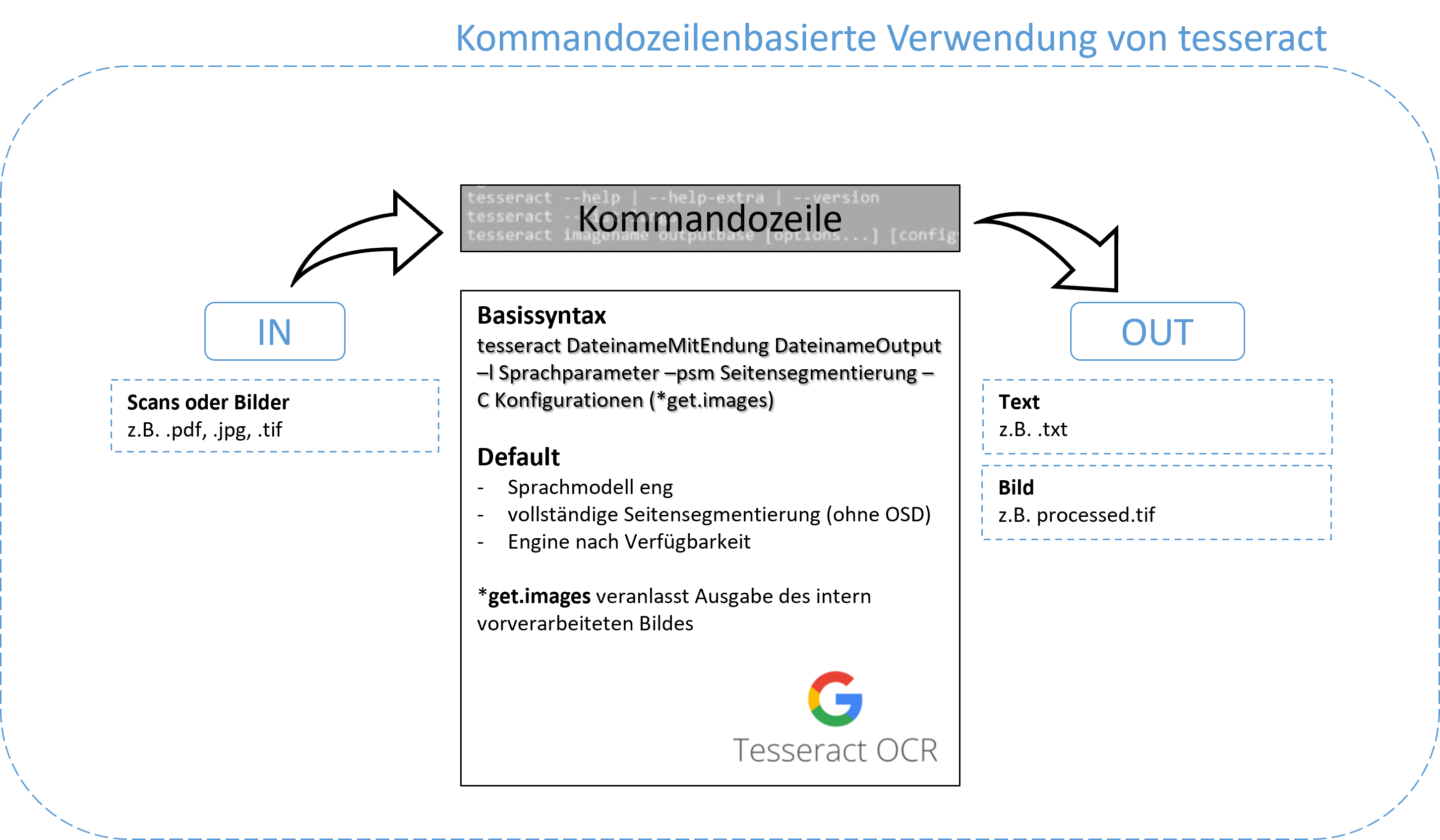
Weitere sinnvolle Befehle zu finden unter: tesseract --help-extra
- Hier geht es zu einer Einführung in die Verwendung der Kommandozeile für Windows, MacOS und Linux.
- Hier geht es zu einer ausführlichen Anleitung zur kommandozeilenbasierten Nutzung von Tesseract.
- Hier geht es zu einer ausführlichen Anleitung zur Installation der Ubuntu Linux Bash unter Windows 10.
Training
Training mit tesseract 5.x 1. README zum Tesseract Training aufrufen 2. Zum Abschnitt Provide Ground Truth navigieren 3. Mithilfe des Python Skriptes split_training_text.py mit text2image notwendige Dateien generieren und abspeichern 4. Dabei anzupassen: Sprache, Schriftart (.otf), sowie die Parameter: ysize (Höhe) und char_spacing (Abstand) 5. Ordner langdata mit deu.training_text befüllen 6. TESSDATA_PREFIX=../tesseract/tessdata make training MODEL_NAME=[insert model name] START_MODEL=[insert lang] TESSDATA=../tesseract/tessdata MAX_ITERATIONS=2000 anpassen, um Training auszuführen 7. Mit Anzahl der Wiederholung experimentieren (Overfit vermeiden, Errorrate verringern) 8. Model evaluieren: tesseract data/[insert ground truth folder]/[*].tif stdout --tessdata-dir/[*]/tesstrain/data --psm [insert psm] -l [insert model name] --loglevel ALL (notwendige Parameter anpassen)
- Hier geht es zu einer ausführlichen Anleitung zum Tesseract Training.
- Hier gibt es ein Videotutorial Gabriel Garcia zum Tesseract Training.
- Hier geht es zum im Tutorial referenzierten GitHub Repository.
Training, what else?
Tesseract zu trainieren (oder selbst ein Finetuning für bestimmte Schriftarten) scheint nicht immer die beste Idee zu sein…
Alternative: Verbesserung des Tesseract Standard Modells
- Dateien auf sinnvolle Weise vorverarbeiten (z.B. mit ImageMagick).
- Geeignete Sprach- und Schriftmodelle auswählen (tessdata, tessdata_fast, tessdata_best).
- Geeigneten Modus für die Seitensegmentierung wählen (
--psm 1-13). - Geeigneten Modus für die Engine wählen (Legacy, LSTM).
- Unter Umständen weitere Parameter sinnvoll anpassen (
tesseract --print-parameters)
Wenn alle Stricke reißen: Hilfe im Forum suchen!
Read
III. OCR4ALL
Geschichte, Grundlagen und Installation
OCR4all wurde primär zur Digitalisierung sehr früh gedruckter Dokumente entwickelt, da viele Texterkennungsprogramme zumeist nicht in der Lage sind, die hohe Komplexität der Textsorten und Layoutkonzepte solcher Texte zu bewältigen. Durch die Bündelung verschiedener Werkzeuge in einer einheitlichen Benutzeroberfläche entfällt das Wechseln zwischen verschiedenen Programmen. Aufgrund seiner intuitiven Bedienweise und des semi-automatisierten Workflows richtet sich OCR4all ausdrücklich auch an Nicht-Informatiker*innen. Quelle: OCR4all—An Open-Source Tool Providing a (Semi-)Automatic OCR Workflow for Historical Printings
> The workflow starts with the Preprocessing of the relevant image files. Layout segmentation (so-called Region Segmentation carried out with LAREX and Line Segmentation follow. Next is the Text Recognition which is carried out with Calamari. The final stage is the correction of the recognized texts the so-called Ground Truth Production. This Ground Truth is then the foundation for creating work-specific OCR models in a training module. Therefore OCR4all entails a full-featured OCR workflow. > Zur zitierten Quelle
Durch die Ausführung mit Docker bleiben Bild-und Textdaten auf dem eigenen System. Selbst wenn OCR4all auf einem Server installiert und kollaborativ genutzt wird, ist die Nutzung von OCR4all aus urheberrechtlicher Sicht vollkommen unbedenklich. Quelle: forTEXT zu OCR4all
- Hier geht es zu einer ausführlichen Installationsanleitung für Docker
- Hier geht es zu einer ausführlichen Installationsanleitung für OCR4all
- Hier geht es zur in OCR4all eingebundenen ATR (automatic text recognition) engine Calamari, einer Abspaltung von OCRopus
GUI und Standardmodell
- Bilddateien in entsprechend erstelltem Verzeichnis ablegen
- Bilddateien ggf. konvertieren lassen (falls nicht
.png) - Workflow (→ nächster Abschnitt) für Stichprobe festlegen und ausführen
- Ground Truth Production (LAREX)
Workflow
- Preprocessing
- Noise Removal
- Page Segmentation
- Line Segmentation
- Text Recognition (geeignetes Model)
- Ground-Truth Production
nützliche Shortcuts bei der manuellen Segmentierung: - 3 → rechteckige Textregion oder Zeile eingrenzen - 7 → rechteckige Fläche entfernen - R → Textregion oder Zeile zur Lesereihenfolge hinzufügen

Training
- Zur Anleitung im OCR-Workflow zu Training navigieren
- Ground Truth mithilfe von [LAREX-Editor] erstellen
- Input: Bilddateien mit Textzeilen + GroundTruth (ggf. OCR-Model)
- Der schrittweisen Erläuterung im OCR4all UserGuide folgen, um die Einstellungen zum Training vorzunehmen
Hier geht es zu einem anwendungsorientierten Vortrag zu OCR4all von Dr. Christian Reul (Universität Würzburg) im Rahmen des Transkribathons „Faithful Transcriptions“ von Universitätsbibliothek Leipzig und Staatsbibliothek zu Berlin
IV. Workflow-Evaluation
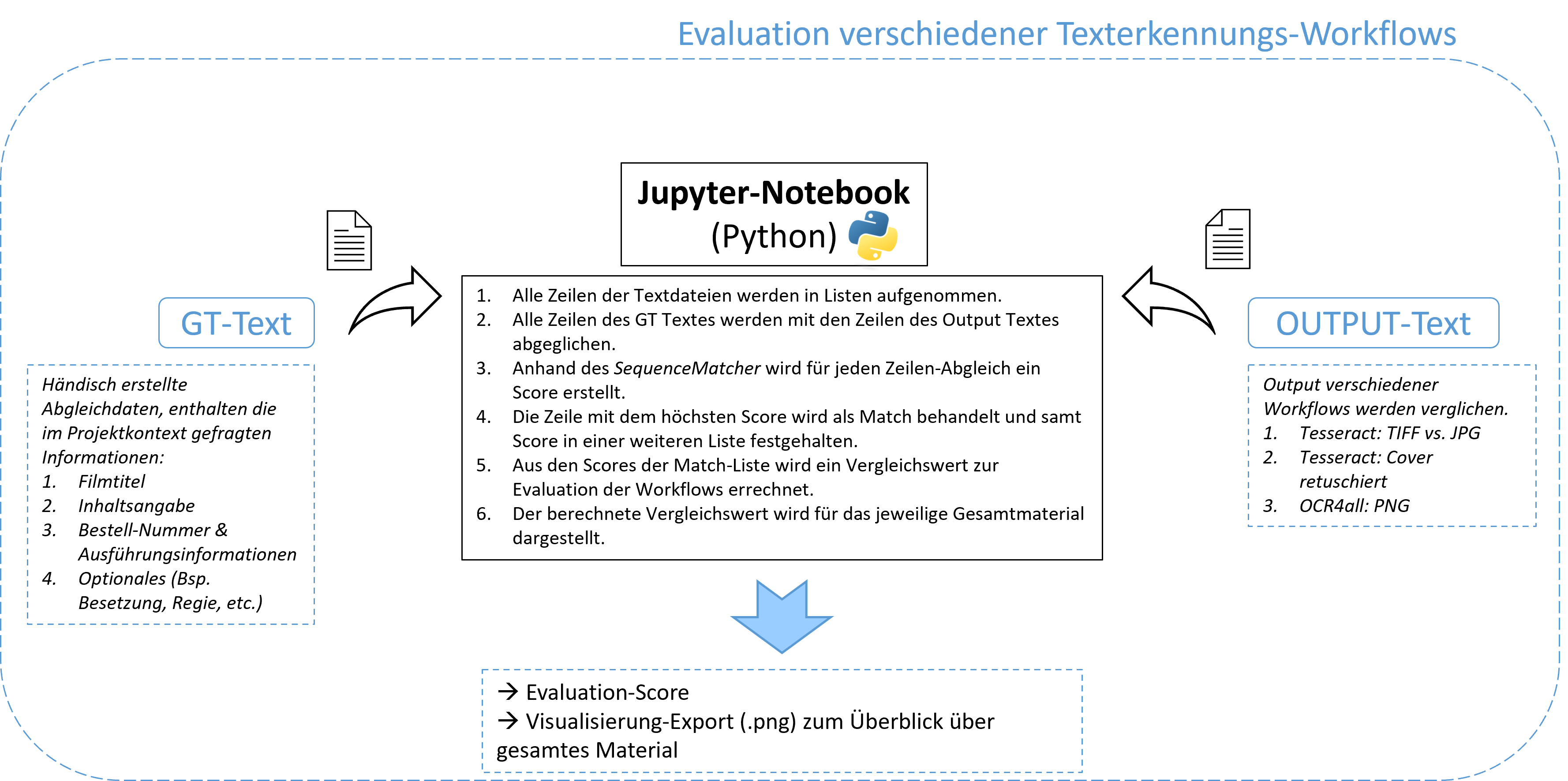
Stichprobenauswahl - ca. 10% des Materials - repräsentative Auswahl - pragmatisches Kriterium: enthält der Output die minimal notwendigen (zum Abgleich als -gt.txt festgehaltenen) Informationen?
Evaluationsvorgehen - Jupyter-Notebook mit Python-Skript & Dokumentation - Abgleich zweier .txt Dateien (Output = -out.txt → Ground-Truth = -gt.txt) - Auswertung mithilfe der SequenceMatcher Library - Visualisierung mithilfe der Matplotlib Library
V. Anwendungsbeispiel Super-8-Filmkataloge
Kontext: Digitalisierungsvorhaben des DiCi-Hub zur Datenextraktion (und anschließende Datenbank-Überführung) aus Super-8-Filmkatalogen verschiedener Anbieter (UFA, marketing film, piccolo)
Fragestellung: Welcher Workflow zur Texterkennung erweist sich für das o. g. Material als sinnvoll?
- Einarbeitung in computerbasierte Texterkennung
- Einarbeitung in Tesseract
- Kommandozeilenbasierte Verwendung von Tesseract
- Kommandozeilenbasierte Vorverarbeitung des Bildmaterials (ImageMagick)
- Einarbeitung in Tesseract Parameter
- Verbesserung des Outputs
- Entwicklung eines Evaluationsskriptes (Jupyter Notebook, Python)
- Einarbeitung in Tesseract Training
- Einarbeitung in OCR4all (& Docker)
- Verwendung des Default-Workflows von OCR4all
- Einarbeitung in OCR4all Training
- Evaluation der Workflows
Hier geht es zur ausführlichen Projektdokumentation.
Lizenzierung

Weiternutzung als OER ausdrücklich erlaubt. Dieses Werk und dessen Inhalte (Text, Abbildungen sowie Befehle und Code) sind - sofern nicht anders angegeben - lizenziert unter https://creativecommons.org/licenses/by/4.0/deed.de.
Nennung bitte wie folgt: How to: computerbasierte Texterkennung von Merle-Sophie Thoma (2022), Lizenz: https://creativecommons.org/licenses/by/4.0/deed.de.