Projekt-Dokumentation: Workflows zur Texterkennung mit Tesseract und OCR4all am Beispiel von Super-8-Filmkatalogen des Anbieters UFA
Teil I: Tesseract Standardmodell & Bild-Vorbearbeitung
About: Textdigitalisierung, OCR und Tesseract
- Einstieg: Möglichkeiten der Textdigitalisierung (ForText)
- Einstieg: OCR und Tesseract
- Überblick: Tesseract Wiki
1. Vergleich: Parameter (Stichprobe)
Pagesegmentation & Engine: Beispiel KaUf_77_2_0006
%Tesseract%/tesseract KaUf_77_2_0006.jpg KaUf_77_2_0006-out -l deu [psm][oem] get.images
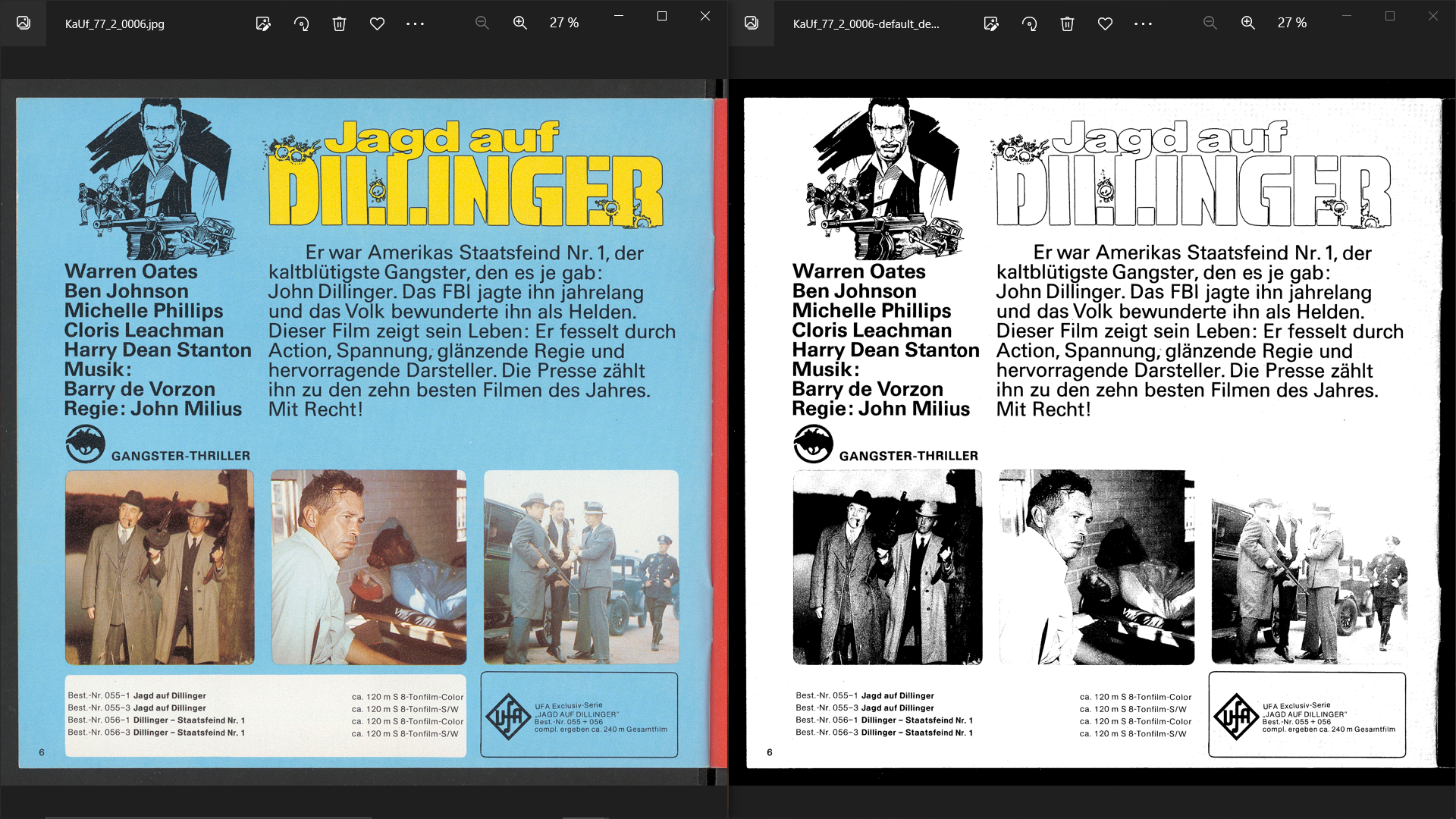
Page Segmentation (– psm):
Quelle: Tesseract Page Segmentation
0 Nur Ausrichtung und Skript-Erkennung: Metainformationen (Rotation, Schrift, etc.) 1 Automatische Seitensegmentierung mit OSD 2 Automatische Seitensegmentierung, aber keine OSD, oder Texterkennung (OCR) 3 Vollständige automatische Seitensegmentierung, aber keine OSD (Default) 4 Behandelt die Vorlage als eine einzelne Textspalte mit unterschiedlichen Zeichengrößen 5 Behandelt die Vorlage als einzelnen einheitlichen Textblock im Blocksatz 6 Behandelt die Vorlage als einheitlichen Textblock 7 Behandelt das Bild als einzelne Textzeile 8 Behandelt das Bild als einzelnes Wort 9 Behandelt das Bild als einzelnes, im Kreis geschriebenes Wort 10 Behandelt das Bild als einzelnes Zeichen 11 Reiner Text, findet so viel Text wie irgend möglich, ohne spezielle Richtung oder Reihenfolge 12 Reiner Text, mit OSD (siehe Option 0) 13 "Raw line" - behandelt das Bild als einzelen Textzeile, ohne weitere tesseract-spezifische Verarbeitungen anzuwenden
OCR engine mode (– oem):
0 nur Legacy Engine 1 nur Neural Nets LSTM Engine 2 Legacy + LSTM Engines 3 Default, nach Verfügbarkeit
Configuration Variables (- c)
%Tesseract%/tesseract --print-parameters > paramters.txt
2. Vergleich: Bildvorverarbeitung (UFA .tif komplett)
for %i in (D:\UFA_SDF\KaUf_*\TIFF\*.tif) do tesseract.exe "%i" "%i-out" -l deu get.images
move *.processed.tif C:\[*]\Tesseract-OCR\processed_images
Read
Problematik Vorverarbeitung: Beispiel KaUf_77_2_0040
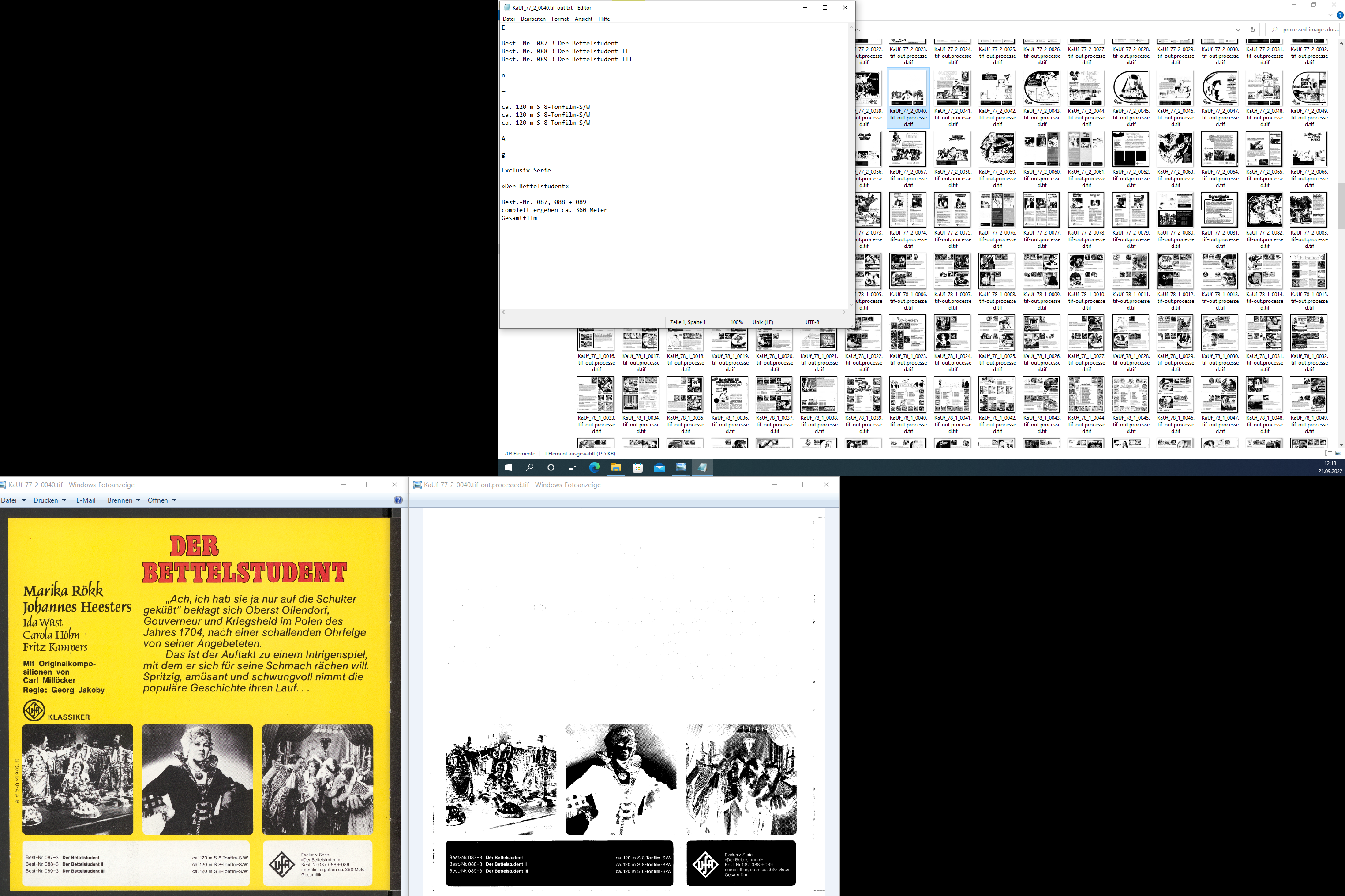
Zusammengefasst
Grundsätzlich muss je nach Eingabebild der zu verwendende Schwellenwertalgorithmus ausgewählt werden. Tesseract verwendet die Otsu-Methode für die Schwellenwertberechnung, da die Eingabe in Tesseract für die Textextraktion im Allgemeinen homogene Bilder aufweist.
Die globale Schwellenwertmethode ist sinnvoll, wenn der Hintergrund keine lokalen Schwankungen im Verhältnis zur Intensität des Vordergrunds aufweist. Ein lokaler Schwellenwert ist hingegen notwendig, wenn die Intensitätsunterschiede zwischen Hintergrund und Ziel lokal variieren.
Obwohl Tesseract die Otsu-Methode (globale Schwellenwertbildung) für die Binarisierung verwendet, kann man Bilder mit lokalen Schwellenwertmethoden vorverarbeiten, um ein besseres Ergebnis von Tesseract zu erhalten.
Andere Optionen
Seit Tesseract 5.0.0 zwei neue Leptonica-basierte Binarisierungsmethoden: Adaptive Otsu und Sauvola.
tesseract --print-parameters | grep thresholding_
relevante konfigurierbare Parameter:
| parameter | default | modification |
|---|---|---|
| thresholding_method | 0 | 0=Otsu, 1=LeptonicaOtsu, 2=Sauvola |
| invert_threshold | 0.7 | For lines with a mean confidence below this value, OCR is also tried with an inverted image |
| thresholding_debug | 0 | Debug the thresholding process |
| thresholding_window_size | 0.33 | Window size for measuring local statistics (to be multiplied by image DPI). This parameter is used by the Sauvola thresholding method |
weitere: thresholding_kfactor 0.34 | Factor for reducing threshold due to variance. This parameter is used by the Sauvola thresholding method. Normal range: 0.2-0.5
thresholding_tile_size 0.33 | Desired tile size (to be multiplied by image DPI). This parameter is used by the LeptonicaOtsu thresholding method
thresholding_smooth_kernel_size 0 | Size of convolution kernel applied to threshold array (to be multiplied by image DPI). Use 0 for no smoothing. This parameter is used by the LeptonicaOtsu thresholding method
thresholding_score_fraction 0.1 | Fraction of the max Otsu score. This parameter is used by the LeptonicaOtsu thresholding method. For standard Otsu use 0.0, otherwise 0.1 is recommended
außerdem möglich:
- ImageJ Auto Threshold (java)
- OpenCV Image Thresholding (python)
- scikit-image Thresholding Dokumentation (python)
3. Vorverarbeitung (Auswahl)
Worst of: Tesseract Preprocessing


Read
Grayscaling
Grayscale Method for %i in () do magick "%i" -colorspace Gray "%i-grayscale" 
Saturation
Brightness Modulation for %i in () do magick "%i" -modulate 100,0 "%i-sat0" 
4. Threshold Red 80%
Threshold
Stichprobe KaUf_76_2_0038
magick KaUf_76_2_0038.tif -channel red -threshold 80% KaUf_76_2_0038-out.tif magick KaUf_76_2_0038-out.tif -modulate 100,0 KaUf_76_2_0038-outfinal.tif %Tesseract%/tesseract KaUf_76_2_0038-outfinal.tif final.tif -l deu get.images

Auswahl
for %i in (C:\Users\[*]\Desktop\tess_test_config\*.tif) do magick "%i" -channel red -threshold 80% "%i-thresh.tif" for %i in (C:\Users\[*]\Desktop\tess_test_config\threshold\*-thresh.tif) do magick "%i" -modulate 100,0 "%i-out.tif" for %i in (C:\Users\[*]\Desktop\tess_test_config\threshold\*-out.tif) do %Tesseract%\tesseract "%i" "%i-threshR80" -l deu get.images
5. Workflow: Magick & Tesseract
1. Threshold Red 80% >Allen Pixelwerten (genauer gesagt, die mit -channel eingestellten Kanäle), die den angegebenen Schwellenwert überschreiten, wird der maximale Kanalwert zugewiesen, während alle anderen Werte den minimalen Wert erhalten.
Weniger Verluste ohne Farb-Threshold Parameter?
2. Saturation 0% >Die Sättigung bestimmt die Menge an Farbe in einem Bild. Ein Wert von 0 ergibt beispielsweise ein Graustufenbild, während ein hoher Wert wie 200 eine sehr bunte, "cartoonhafte" Farbe erzeugt.
3. Tesseract >Die Standardeinstellungen von Tesseract mit dem besten Sprachmodell Deutsch (im LSTM Engine Mode) liefern eine sehr genaue Ausgabe.
Extras: Weitere Verbesserungen?
Read
Improving the Recognition Accuracy of Tesseract-OCR Engine on Nepali Text Images via Preprocessing
Genauigkeit bestimmen
Funktionen Tesseract? Recap Tesseract
PyTesseract >image_to_data Returns result containing box boundaries, confidences, and other information. Requires Tesseract 3.05+. For more information, please check the Tesseract TSV documentation
Image Processing > Among the data returned by pytesseract.image_to_data(): left is the distance from the upper-left corner of the bounding box, to the left border of the image. > top is the distance from the upper-left corner of the bounding box, to the top border of the image. width and height are the width and height of the bounding box. > conf is the model's confidence for the prediction for the word within that bounding box. If conf is -1, that means that the corresponding bounding box contains a block of text, rather than just a single word. > The bounding boxes returned by pytesseract.image_to_boxes() enclose letters so I believe pytesseract.image_to_data() is what you're looking for.
Teil II: Training
About: Tesseract Training
- Tesseract Development Documentation
- Training Tesseract on Custom Data
- Understanding LSTM
- Train Tesseract Model from Scratch
- Train Tesseract OCR in Python
- OCR Tesseract Training Data
- Train Tesseract HTR
- How to train Tesseract
Zusammengefasst
> Neural networks require significantly more training data and train a lot slower than base Tesseract. For Latin-based languages, the existing model data provided has been trained on about 400000 textlines spanning about 4500 fonts. For other scripts, not so many fonts are available, but they have still been trained on a similar number of textlines. Instead of taking a few minutes to a couple of hours to train, Tesseract 4.00 takes a few days to a couple of weeks. Even with all this new training data, you might find it inadequate for your particular problem, and therefore you are here wanting to retrain it.
Quelle: How to train Tesseract
1. Optionen
> Fine tune. Starting with an existing trained language, train on your specific additional data. This may work for problems that are close to the existing training data, but different in some subtle way, like a particularly unusual font. May work with even a small amount of training data. > Cut off the top layer (or some arbitrary number of layers) from the network and retrain a new top layer using the new data. If fine tuning doesn’t work, this is most likely the next best option. Cutting off the top layer could still work for training a completely new language or script, if you start with the most similar looking script. > Retrain from scratch. This is a daunting task, unless you have a very representative and sufficiently large training set for your problem. If not, you are likely to end up with an over-fitted network that does really well on the training data, but not on the actual data.
Quelle: How to train Tesseract
2. Training mit tesseract v5.2:
> Training with tesstrain.sh bash scripts is unsupported/abandoned for Tesseract 5. Please use python scripts from tesstrain repo for training.
Quelle: How to train LSTM/neural networks
Read
Lessons Learned
Tesseract limitations summed in the list. 1. The OCR is not as accurate as some commercial solutions available to us. 2. Doesn't do well with images affected by artifacts including partial occlusion, distorted perspective, and complex background. 3. It is not capable of recognizing handwriting. 4. It may find gibberish and report this as OCR output. 5. If a document contains languages outside of those given in the -l LANG arguments, results may be poor. 6. It is not always good at analyzing the natural reading order of documents. For example, it may fail to recognize that a document contains two columns, and may try to join text across columns. 7. Poor quality scans may produce poor quality OCR. 8. It does not expose information about what font family text belongs to.
Quelle: Tesseract OCR
3. Building Tesseract 5 from Source
Vorteile: Versionskontrolle, Funktionen modifizieren Achtung: These are the instructions for installing Tesseract from the git repository. You should be ready to face unexpected problems.
- Tesseract GitHub-Repository öffnen
- Über die Table of Contents zu Installing Tesseract navigieren
- Über Build Tesseract from Source in die Dokumentation navigieren
- Tesseract GitHub-Repository klonen (Git installieren, falls nötig Linux Bash für Windows aktivieren)
- Installation-Guide folgen (Dependencies, Ubuntu, Leptonica)
- Zu Installing Tesseract from Git wechseln, um Trainingtools zu installieren
- Befehle ab To build Tesseract with training tools, run the following durchführen
Fehlermeldungen:
- Unable to find a valid copy of libtoolize or glibtoolize in your PATH (Issue #259) beheben
- Failed to retrieve available kernel versions (askubuntu) beheben
4. Training Tesseract 5 for a new Font
(Github-Repository zum Tutorial)
- README zum Tesseract Training aufrufen
- Zum Abschnitt Provide Ground Truth navigieren
- Mithilfe des Python Skriptes split_training_text.py mit text2image notwendige Dateien generieren und abspeichern
- Dabei anzupassen: Sprache, Schriftart (.otf), sowie die Parameter: ysize (Höhe) und char_spacing (Abstand)
- Ordner langdata mit deu.training_text befüllen
TESSDATA_PREFIX=../tesseract/tessdata make training MODEL_NAME=[insert model name] START_MODEL=[insert lang] TESSDATA=../tesseract/tessdata MAX_ITERATIONS=2000anpassen, um Training auszuführen- Mit Anzahl der Wiederholung experimentieren (Overfit vermeiden, Errorrate verringern)
- Model evaluieren:
tesseract data/[insert ground truth folder]/[*].tif stdout --tessdata-dir/[*]/tesstrain/data --psm [insert psm] -l [insert model name] --loglevel ALL(notwendige Parameter anpassen)
Auswahl der Schriftart(en)
1. Welche Schriftarten führen (möglicherweise) zu schlechterem Ouput? 
Mögliche Schriftarten: 1. Placard Next Round Bold by Monotype 2. Placard Next Round Compressed Bold by Monotype 3. Gill Sans Nova Condensed Ultra Bold by Monotype 4. Aachen SH Bold by Scangraphic Digital Type Collection 5. Dance Lesson JNL by Jeff Levine 6. Pudgy Puss NF by Nick's Fonts 7. Typewriter Serial Extra Light by SoftMaker 8. Dirty Sundae Bold by Fenotype
2. Welche verfügbaren Schriftart(en) repräsentieren Gemeinsamkeiten o.g. Schriftarten?
Möglichkeit 1: Placard Next Round (Compression) Bold by Monotype > aus Fonts for Tesseract Training: […] PistolShot LT Std Bold Placard MT Std Bold Placard MT Std Medium Plantin Head MT Std Bold […]
Zu MyFonts by Monotype: Placard Next
Möglichkeit 2: Aachen SH Bold by Scangraphic > aus Fonts for Tesseract Training: Aachen Std Bold Aachen Std Medium Abadi MT Std Bold […]
Möglichkeit 3: Gill Sans Nova Cond Bold > aus Fonts for Tesseract Training: Gill Sans MT Std Medium Italic Gill Sans Shadowed MT Std Light Gill Sans WGL Bold Gill Sans WGL Bold Italic […]
3. Welche Schriftart für Training geeignet (=notwendiges Material gegeben)? Gill Sans Nova Cond Bold - Microsoft Font
Notwendiges Trainingsmaterial
- Font als .otf Datei
- Python Skript split_training_text.py zur zeilenweisen Separation und Anwendung von text2image
- Ordner MODEL_NAME-ground-truth: .tiff, .box, .txt Dateien
- Ordner tessdata: default Inhalt + deu.traineddata
- Ordner langdata_lstm: deu
Read
LSTM Neural Networks:
Da die Programme gängiger Texterkennungssoftware häufig auf dem Konzept des LSTM (Long Short Term Memory) aufbauen, ist es sinnvoll, dieses zumindest im Ansatz nachvollziehen zu können. Im Kontext des überwachten maschinellen Lernen macht sich das lange Kurzzeitgedächtnis darum die Technik der Backpropagation zunutze. Auf diese Weise vergessen die künstlichen neuronalen Einheiten (Units) Informationen nicht, wie bei herkömmlichen RNN, sondern können aufgrund eines kodierten und gewichteten Erinnerungsvermögens auf zurückliegende Informationen zugreifen und somit Lernfähigkeit und Resultate maßgeblich verbessern.
Read
5. Training, what else?
- Workflow: Blacklist mit Sonderzeichen → @, ©, ®, $ etc. blacklisten, damit Gesamtoutput verbessern? (Encoding Error)
- Workflow: Coverbild-Retusche → Coverbilder ausblenden, damit Gesamtoutput verbessern?
- Workflow: Finetune-Training für Cover-Bild Schriftarten → Output für Coverbilder, damit Gesamtoutput verbessern?
- Workflow: Text Detektion → Segmentierung mit GUI (z.B. von diesen) oder mit anderer Software (z.B.: vielleicht so? oder hiermit?) verbessern
- Workflow: OCR mit OCR4all
Blacklist mit Sonderzeichen
tesseract: -l deu+Fraktur -c tessedit_char_blacklist="*,@,©,®,$"
Fehlermeldungen: 1. utf-8-codec-cant-decode-byte-0xed: change encoding='utf8' to encoding='latin1' 2. IOPub data rate exceeded: run notebook by jupyter notebook --allow-root --NotebookApp.iopub_data_rate_limit=1.0e10
Tesseract GUIs
- Rescribe: absolut user-unfreundlich
- Normcap: screen capture tool
- VietOCR: see rescribe
- OCR2Text: PDF Input
- Tesseract4java: Fraktur
- ImageTrans: Comics
OCR4all
- Docker installieren
- OCR4all installieren
- Bilddateien intern konvertieren lassen (tif → png)
- Workflow für Stichprobe festlegen und ausführen
- Ground Truth Production (LAREX)
- optional: Training durchführen
Workflow 1. Preprocessing 2. Noise Removal 3. Segmentation 4. Line Segmentation 5. Recognition (geeignetes Model) 6. Ground-Truth Production 7. Training (optional)
LAREX-Editor Oberfläche 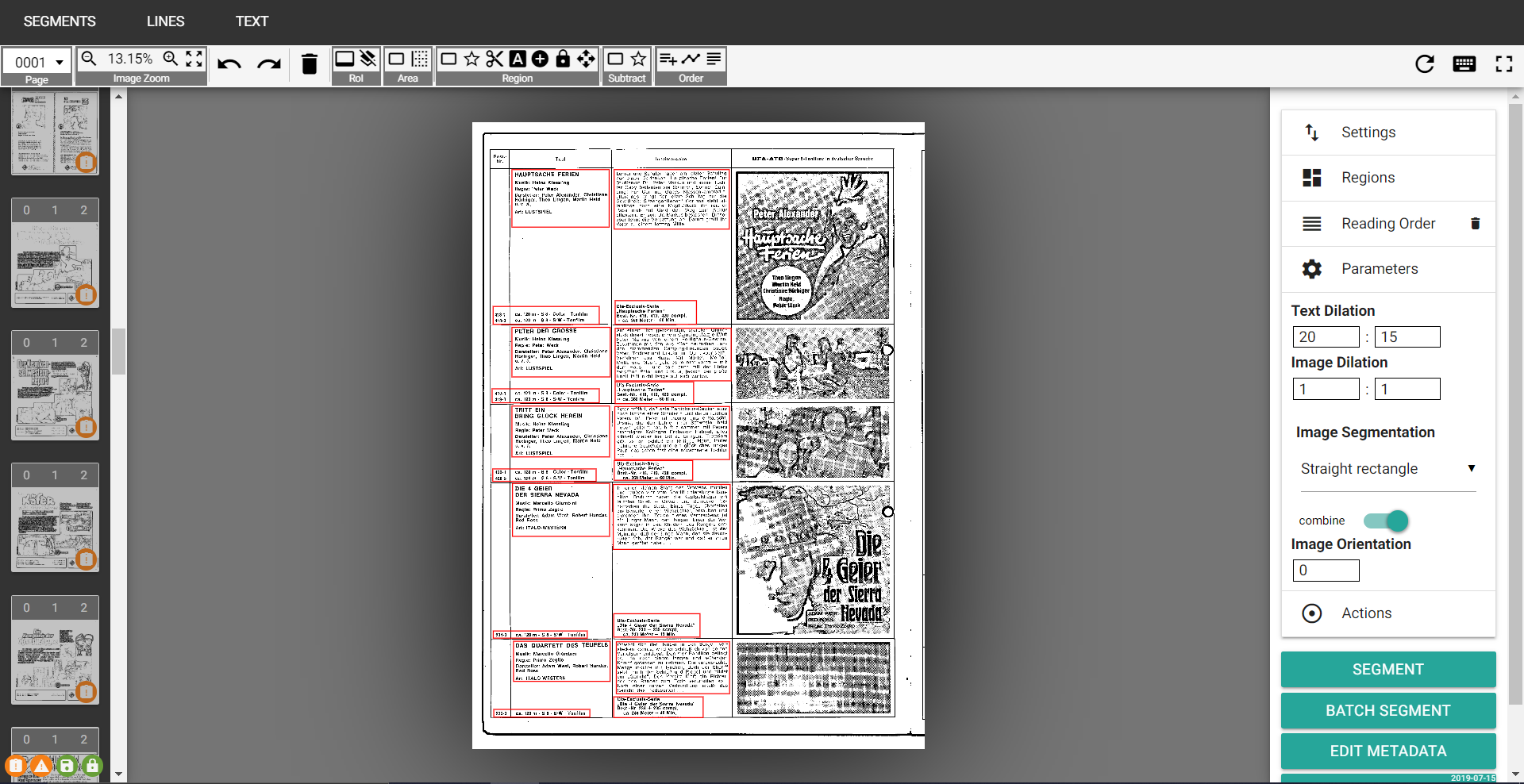
Problem bei der Durchführung Einige der Seiten (Problemfälle: p16, p19, p29, p32, p37, p42, p54, p57) sorgen bei der Seiten- und Zeilensegmentierung für problematischen Output, da die Reihenfolge (auch manuell) nicht korrekt zugeordnet werden kann.

Read - OCR4all bei ForText - OCR Introduction - Systemanforderungen - WSL2 installieren - Calamari-OCR Modelle
Teil III: Vergleich, Nachbearbeitung & Datenbank
1. Ergebnisse und Vergleich
Stichprobe
- ca. 10% (2 bis 4 x16)
- Auswahlkriterien: 4 (-Deckblatt/ Inhalt)
- Vergleich: -gt.txt vs. -out.txt
- Problem: Reihenfolge?
- Was ist das Minimum?
- Titel
- Handlung
- Bestellinformationen
- extra: Creditangaben, Genre (wenn gegeben)
- extra: UFA Serie Information
- keine Bilder und Zusatzinformationen
Fragen - Enthält Tesseract-Output die projektspezifisch notwendigen Zeilen? - Besteht die Möglichkeit, die Reihenfolge der Zeilen miteinzubeziehen? - Mit welchem Algorithmus lässt sich die Genauigkeit bestimmen? - Wie lassen sich Line Matches aus GT Liste herausnehmen? - Anderer Ansatz: Müll-Abgleich?
→ pragmatisch: keine Reihenfolge, SequenceMatcher als Vergleichswert
Skript
Das Python Skripte sowie Dokumentation und Datensätze zu finden unter: GitHub super8_project
SequenceMatcher-Funktion (difflib Modul) Quelle: SequenceMatcher in Python
> Given two input strings a and b, > > - ratio( ) returns the similarity score ( float in [0,1] ) between input strings. It sums the sizes of all matched sequences returned by function get_matching_blocks and calculates the ratio as: ratio = 2.0*M / T , where M = matches , T = total number of elements in both sequences > - get_matching_blocks( ) return list of triples describing matching subsequences. The last triple is a dummy, (len(a), len(b), 0). It works by repeated application of find_longest_match( ) > - find_longest_match( ) returns a triple containing the longest matching block in a[aLow:aHigh] and b[bLow:bHigh]
Varianten im Stichprobenvergleich
- TIFF vs. JPG (BestStandard?) tesseract:
-l deu+FrakturTIF: ~91.34% JPG: ~90.79% - BestStandard vs. händische Retusche BestStandard: ~91.34% (händische) Retusche: ~84,36%
- BestStandard vs. OCR4allDefault BestStandard: ~91.34 OCR4All (default): ~91,2
Vergleichswert für Workflows bei UFA Katalogen
- Alternative: zur Evaluation der Workflows (z.B. OCR Evaluation with CER & WER)
- Alternative: zur Evaluation der Workflows Reihenfolge miteinbeziehen
- Alternative: gematchte Zeilen aus Output löschen (auskommentiert im Skript)
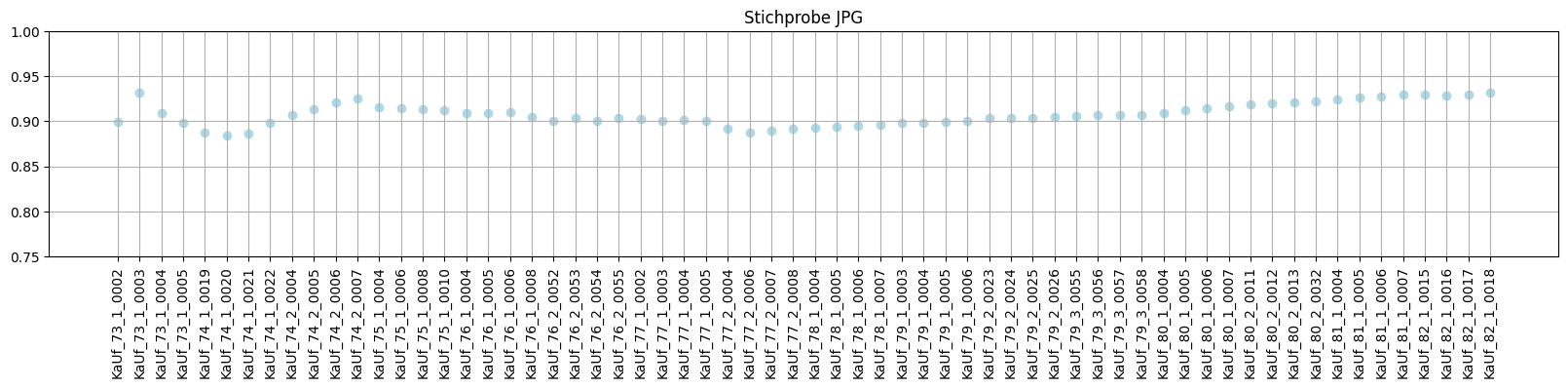
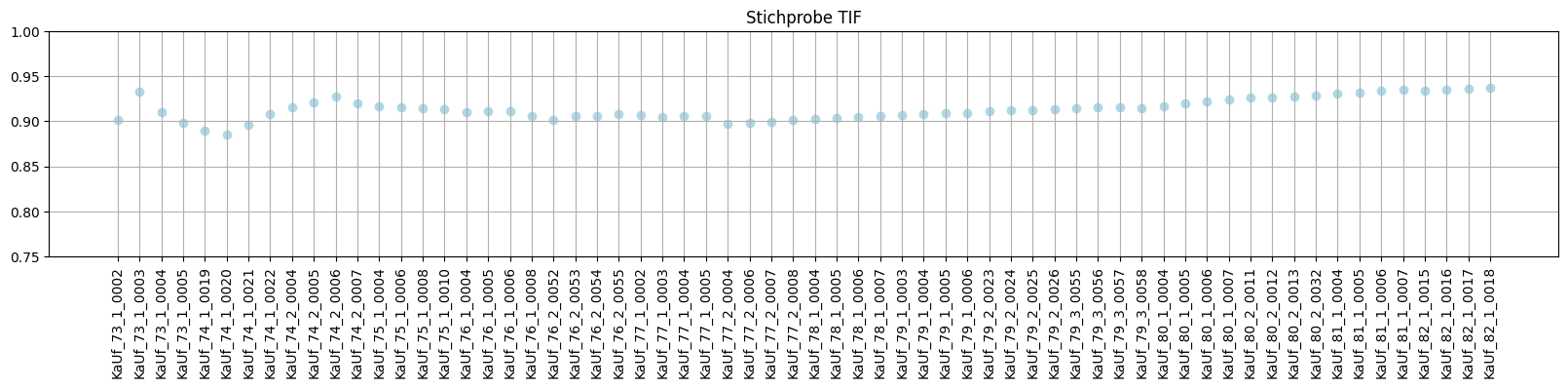
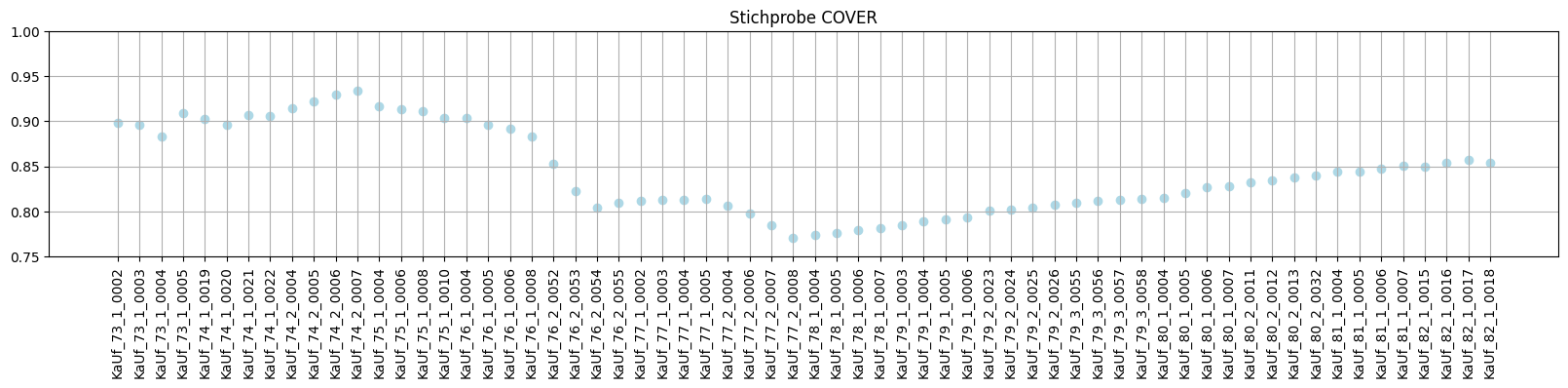
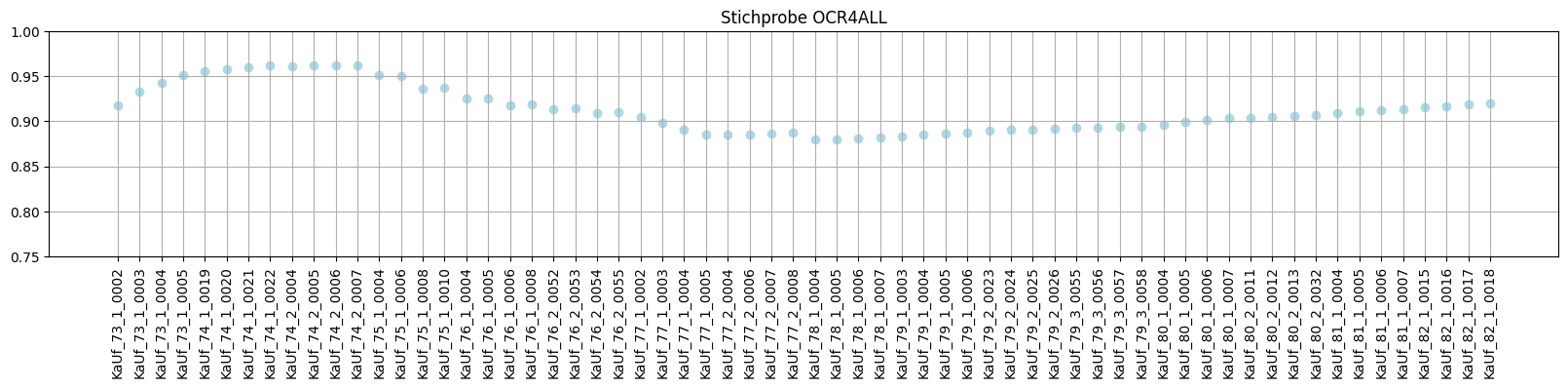
Auswertung
Das kommandozeilenbasierte Tesseract im Standardmodell bietet mit dem geringsten Arbeitsaufwand und einer überschaubaren Bildvorverarbeitung den besten Output. Vermutlich performt OCR4all bzgl. der Reihenfolge besser, was sich allerdings im Rahmen dieser Evaluation nicht auswerten ließ. Zudem scheint im Zusammenhang mit der Segmentierung ein bisher nicht behobener Fehler vorliegen, was die Zuordnung der Reihenfolge für den Output erheblich beeinflusst. Trainieren eines eigenen Modells (mit tesseract sowie OCR4all) wäre mit einem unverhältnismäßigen zeitlichen und/oder finanziellen Aufwand verbunden.
Könnte nützlich sein
- über Kommandozeile alle Einzel-txt-Files zu einem kopieren:
copy /b *.txt Gesamttext.txt - Stapelweise Umbenennung von Dateien in einem Ordner über Kommandozeile/Windows Powershell:
dir | %{$x=0} {Rename-Item $_ -NewName "TestName$x.jpg"; $x++ } - Linux Folder System Explained

Dieses Werk und dessen Inhalte (Text, Abbildungen sowie Befehle und Code) sind - sofern nicht anders angegeben - lizenziert unter https://creativecommons.org/licenses/by/4.0/deed.de.
Nennung bitte wie folgt: Projekt-Dokumentation: Workflows zur Texterkennung mit Tesseract und OCR4all am Beispiel von Super-8-Filmkatalogen des Anbieters UFA von Merle-Sophie Thoma (2022), Lizenz: https://creativecommons.org/licenses/by/4.0/deed.de.