Daten bereinigen und anreichern mit OpenRefine
Diese Lecture-Einheit zielt darauf ab, unseren Übungsdatensatz weiter zu explorieren sowie Unregelmäßigkeiten schnell zu erkennen und zu vereinheitlichen. Hierzu stellen wir das freie Programm OpenRefine vor und zeigen anhand unseres Übungsdatensatzes die Grundfunktionen. Neben der Datenbereinigung gehen wir auf die Datenanreicherung mit OpenRefine aus externen Datenquellen wie WikiData ein.
Was ist OpenRefine?
- Funktion: OpenRefine ist ein Werkzeug, das unter anderem dazu geeignet ist, um einen Überblick über Datensätze zu erhalten, sie zu bereinigen, mit externen Daten anzureichern oder in andere Formate zu exportieren. Hierfür wird ein Datensatz in das Programm geladen.
- Open Source Tool, kann kostenfrei genutzt werden, verfügbar für Windows, Linux und Mac OS
- Es sind keine Programmierkenntnisse notwendig, jedoch sind für die fortgeschrittene Nutzung Kenntnisse einer Programmiersprache, regulärer Ausdrücke und zur Datenbankabfrage von Vorteil.
- Alternative zu Tools wie Excel und Programmiersprachen wie Python und R, mithilfe derer ebenfalls Daten bereinigt werden können.
Installation
Es erfolgt keine Installation im klassischen Sinne. Das Programm kann für das eigene Betriebssystem von der Webseite heruntergeladen werden. Im Fall von Windows sollte geprüft werden, ob die Version mit oder ohne der Programmiersprache Java benötigt wird. Der Download besteht aus einem komprimierten Ordner. In komprimierten Ordnern können mehrere Dateien bereitgestellt oder verschickt werden und die Größe der einzelnen Dateien ist kleiner. Der heruntergeladene Ordner muss, damit OpenRefine ausgeführt werden kann, dekomprimiert werden. Das erfolgt in den meisten Fällen, dass man mit der rechten Maustaste auf den Ordner klickt und im Menü “entpacken” auswählt. Der Begriff “entzippen” ist ebenfalls gängig.
OpenRefine - Grundfunktionen
Wenn OpenRefine gestartet wird, öffnen sich zwei Fenster: ein Terminalfenster und ein neuer Tab im Standardbrowser. Beide Fenster werden benötigt, damit das Programm läuft, sie dürfen nicht geschlossen werden. Im Terminal werden die einzelnen Arbeitsschritte im Programm angezeigt. Im Browserfenster wird mit dem Programm interagiert.
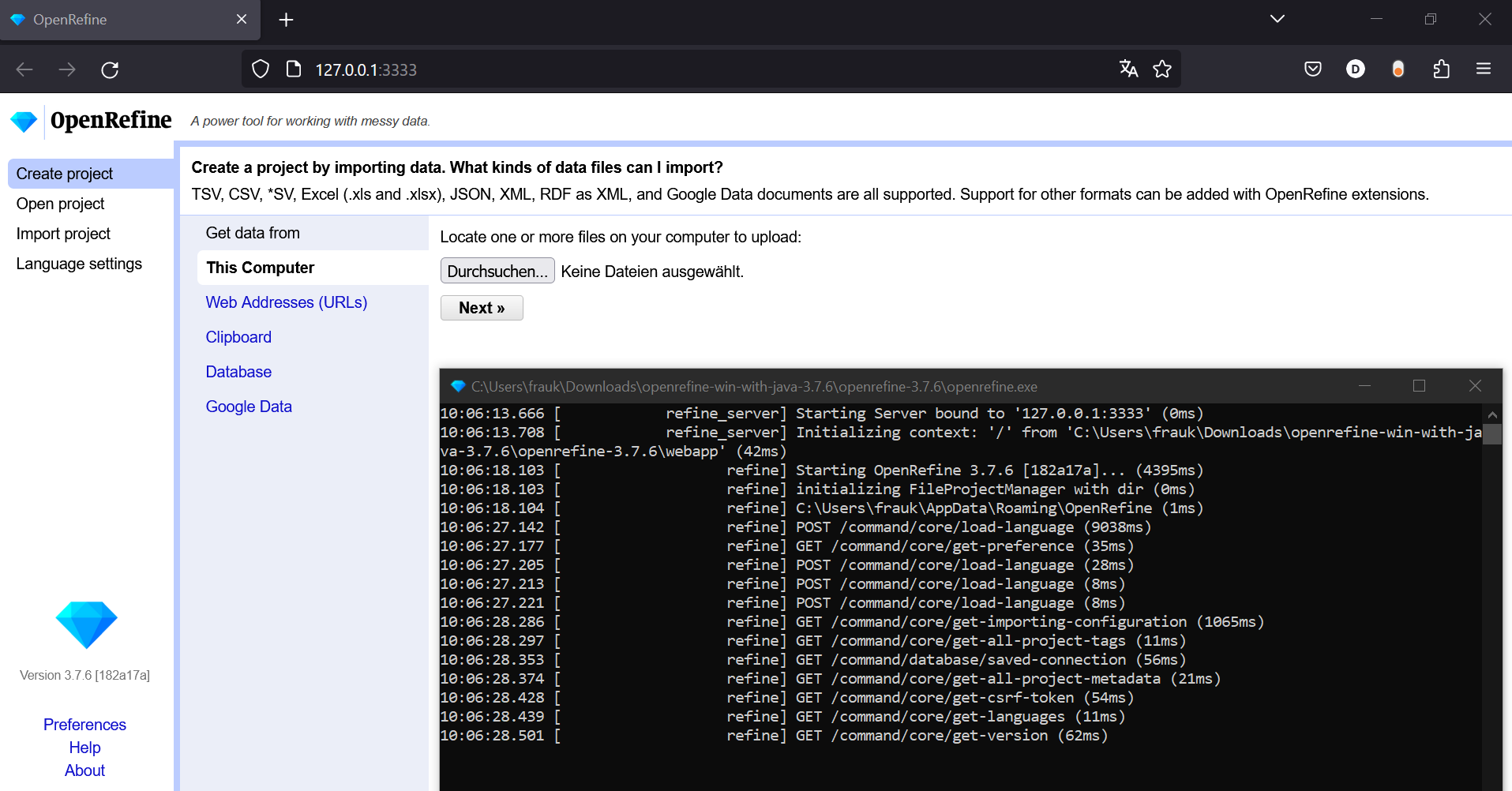
Ein Projekt erstellen
Das Öffnen eines Datensatzes, der lokal vorliegt, erfolgt unter dem voreingestellten Menü “Create project” (linke Spalte). Der Datensatz kann mit “Durchsuchen” ausgewählt werden. Mit “Next” wird der Vorgang bestätigt.
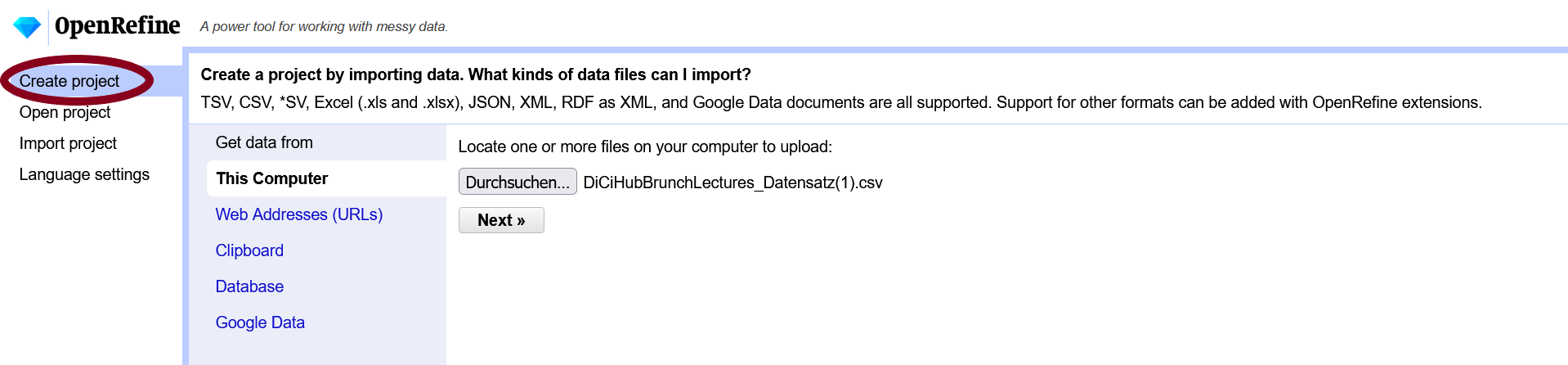
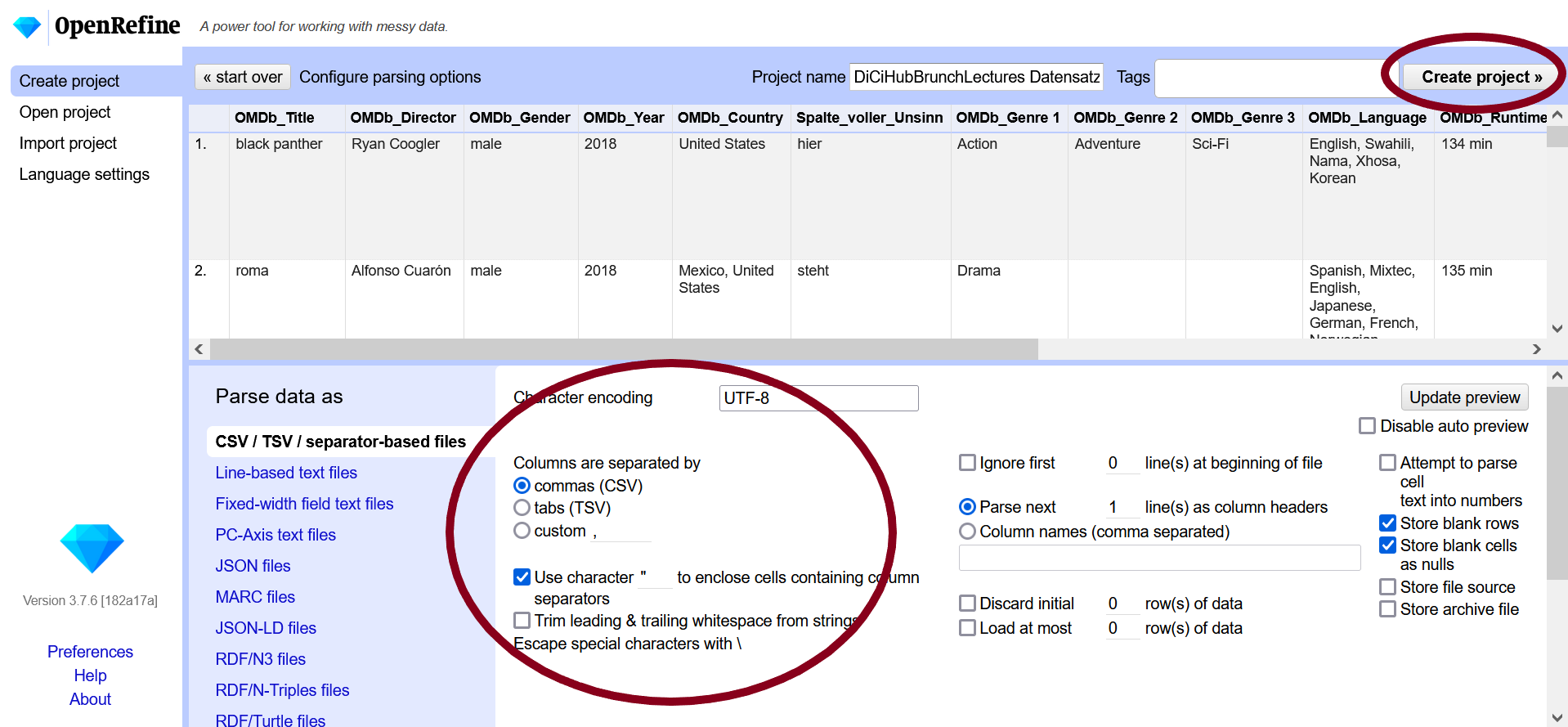
Es öffnet sich die Vorschau des Datensatzes. In dieser kann geprüft werden, ob die Daten korrekt eingelesen werden. Unter der Vorschau kann unter “CSV/TSV/seperator-based files” geprüft werden, ob das sogenannte “Character Encoding” korrekt ist (unter anderem relevant für die Darstellung von Umlauten) und Trennzeichen korrekt angegeben werden (in unserem Fall ein Komma). Außerdem können der Name des Projektes sowie Schlagwörter vergeben werden. Mit Schlagwörtern können Projekte bei Bedarf besser organisiert werden. Wenn alle Einstellungen korrekt sind, kann rechts oben “Create project” bestätigt werden.
Nachdem das Projekt gestartet wurde, werden euch nur 10 Zeilen angezeigt. Das entspricht der Standardeinstellung. Die Anzahl der angzeigten Zeilen kann über dem Datensatz angepasst werden:
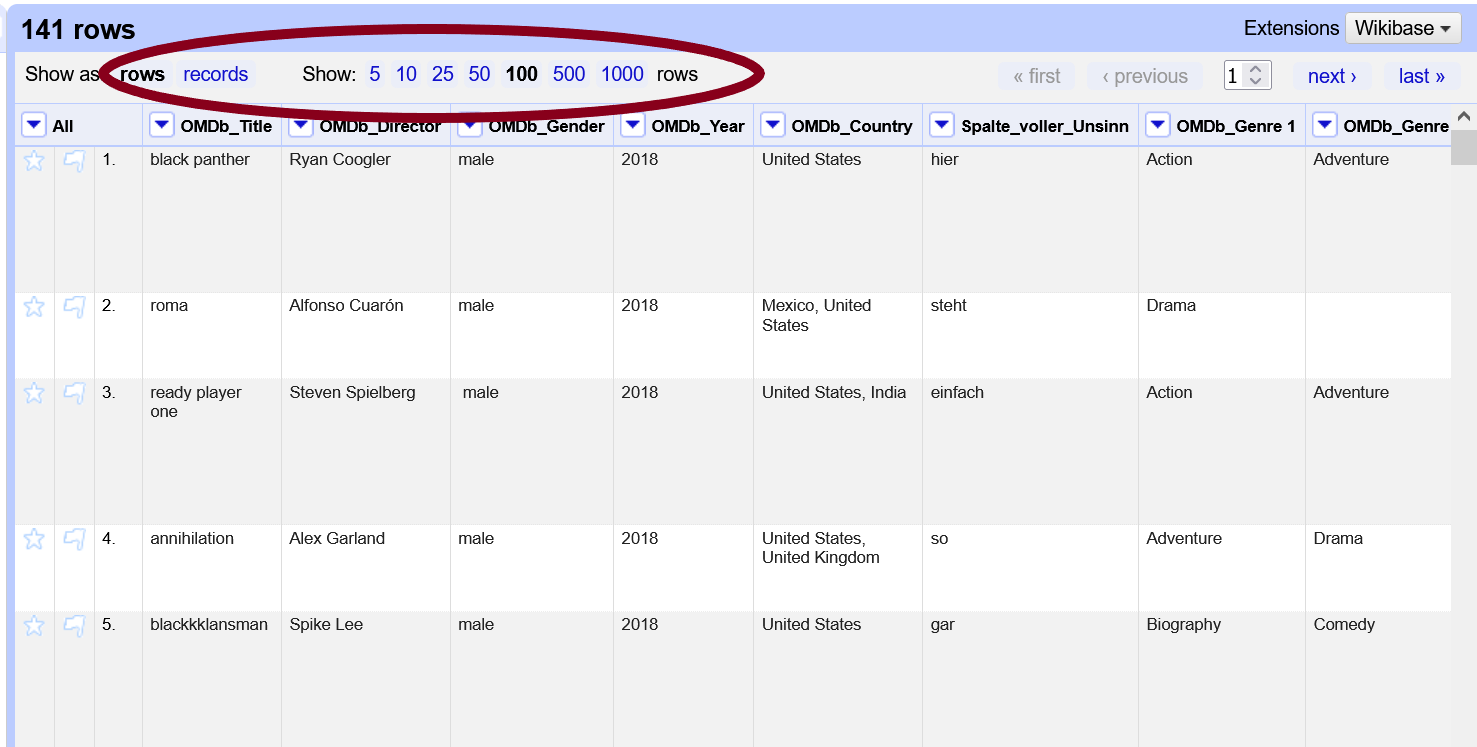
Im Projekt arbeiten
Die Grundfunktionen werden in der Regel über das kleine Dreieck in jedem Spaltenkopf aufgerufen, da der Datensatz meist spaltenweise bearbeitet wird. Im Untermenü, das sich bei Anklicken öffnet, besteht eine Reihe an Aktionsmöglichkeiten. Der Verlauf der einzelnen Aktionsmöglichkeiten ist in der linken Seitenspalte des Programms aufgeführt, sodass jederzeit einzelne Aktionen rückgängig gemacht werden können. Außerdem öffnet sich in der Seitenspalte bei einigen Aktionen ein Fenster, über das weitere Optionen zur Verfügung stehen bzw. Ergebnisse angezeigt werden. Im Folgenden wird nur ein winziger Ausschnitt gezeigt.
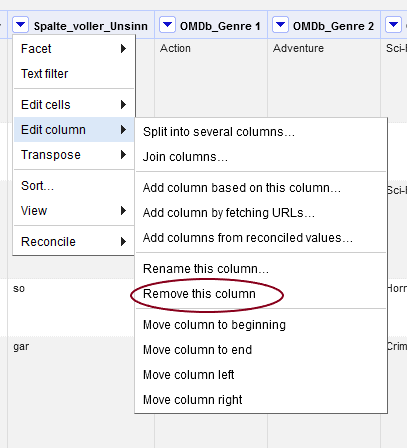
Im Kontextmenü der Spalten kann beispielsweise unter “Edit column” die Spalte_voller_Unsinn gelöscht werden.
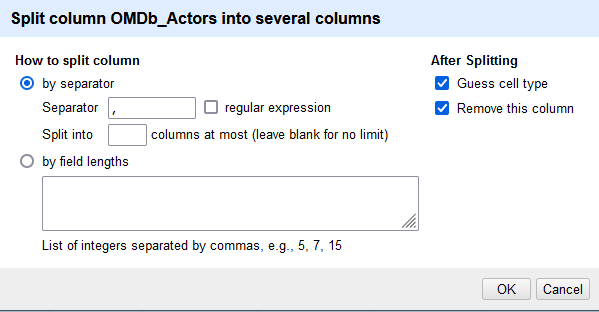
Außerdem können in diesem Menü auch Spalten mit mehreren Einträgen wie OMDb_Actors aufgesplittet werden, sodass jeder Schauspielerin in einer eigenen Spalte steht. Dazu müssen die Trennzeichen eingegeben werden:
Eine praktische Funktion, um sich einen Überblick über die Einträge einer Spalte zu verschaffen, ist die Funktion “Facet”. Am Beispiel der Spalte OMDb_Country bietet sich “Text facet” an, da die Werte in der Spalte Text enthalten.
Die Spalte bleibt unverändert. In der linken Seitenspalte erscheint ein Fenster, in dem die Erbegnisse der Funktion angezeigt werden: Im Fenster wird angezeigt, dass es 58 verschiedenen Angaben zu den Ländern in der Spalte gibt. Die Zahl hinter den Ländern gibt an, wie oft sie eingtragen sind. Die Anzeige kann alphabetisch oder nach Häufigkeit sortiert werden. Um einen Überblick über ähnliche Einträge zu erhalten, kann die “Cluster”-Funktion ausgewählt werden. Diese ist insbesondere praktisch, wenn Rechtschreibfehler oder Inkonsistenzen im Datensatz sichtbar sind oder vermutet werden, da hier mit verschiedenen Algorithmen ebenjene geprüft werden. Es öffnet sich ein neues Fenster:
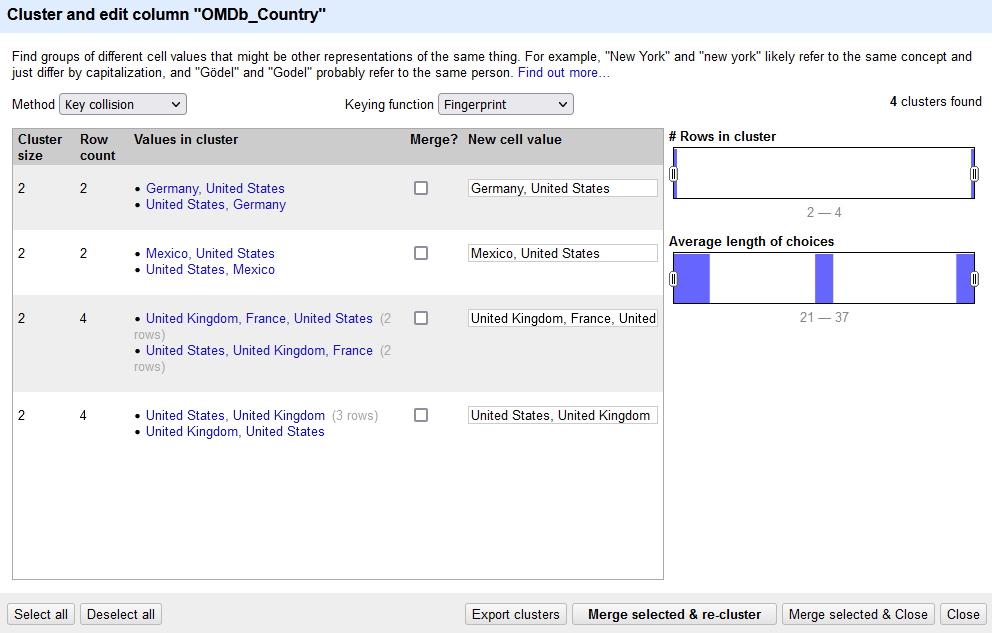
Es wird angezeigt, welche Inkonsistenzen gefunden wurden. Hier handelt es sich um die Reihenfolge der Länder. Es wird angegeben wie viele ähnliche Einträge zu einem Cluster gehören, in wie vielen Zeilen sie gefunden wurden und es wird ein Vorschlag zur Vereinheitlichung angegeben, dem gefolgt werden kann, sofern kein eigener Vorschlag eingetragen werden soll. Die Einträge können gemerged werden, d.h. dass sie vereinheitlicht werden und dann entsprechend nur noch eine Variante der Reihenfolge im Datensatz angezeigt wird. Vor dem mergen sollte geprüft werden, ob es aus fachlicher Perspektive sinnvoll ist!
Einzelne Fehler können auch direkt in den Zellen korrigiert werden. Wenn sich die Maus über einer Zelle befindet, wird die Option “Edit” eingeblendet.
OpenRefine - Daten anreichern
Eine sehr mächtige Information von OpenRefine ist “Reconcile”. Mithilfe dieser Funktion kann der eigene Datensatz mit Daten aus externen Quellen angereichert werden. OpenRefine bietet integriert beispielsweise die automatisierte Anreicherung mit Daten von WikiData an, die im Folgenden gezeigt wird. Eine Anreicherung mit weiteren Daten kann sinnvoll sein, wenn Normdaten benötigt werden oder weitere Informationen, die noch nicht im Datensatz stehen. Wir arbeiten wieder an der Spalte OMDb_Country und wählen die letzte Option “Reconcile” und “Start Reconciling” aus. Es öffnet sich ein Fenster, in dem Wikidata als externe Quelle ausgewählt wird und können nun weitere Einstellungen vornehmen:
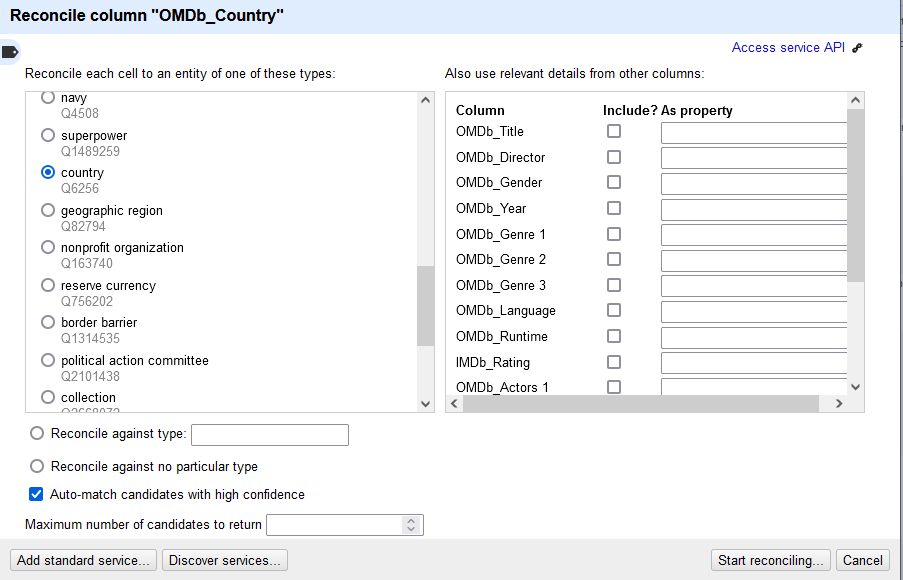
Anhand der Einträge in der Spalte wird ein Vorschlag gemacht, welche Entitäten von Wikidata passen. Da es sich um Länder handelt, wird country gewählt. Das Häckchen bei “Auto-match” candidates with high confidence” kann so bestehen bleiben, da sonst alle Einträge händisch bestätigt werden müssen. Mit “Start reconciling” beginnt die Anreicherung, die unterschiedlich lange Zeit in Anspruch nehmen kann. Das Ergebnis sieht wiefolgt aus:

In der ersten Zeile ist eine Verbindung zum Eintrag “United States of America”, der direkt gematched wurde, weil die Entscheidung eindeutig war. In der zweiten und dritten Zeile sehen wir mehrere Optionen, aus denen wir auswählen können, da hier keine eindeutige Entscheidung möglich war. Die Vorschläge passen jedoch zum Ziel, Länder anzureichern, sondern beziehen sich in den Einträgen, in denen mehrere Länder stehen, auf Ereignisse, die beide Länder einbeziehen. D.h., an dieser Stelle ist ein Anwendungsfall für die Funktion “Undo”. Reconcile kann damit rückgängig gemacht werden, die Spalte gesplittet werden und die die einzelnen Spalten können dann angereichert werden. Hinweis: Bei der Auswahl der Entität von Wikidata, mit der angereichert werden soll, kann es erste Hinweise dafür geben, ob sich die Spalte für das eigene Anreicherungsziel eignet.
Hinweis zum Abschluss
Hier wurde nur die Spitze des Eisberges vorgestellt. Es gibt eine Vielzahl von weiteren Funktionen und Möglichkeiten, die in der Dokumentation oder in Foren erklärt werden.
Alle Screenshots wurden von Frauke Pirk erstellt. Zuletzt bearbeitet am 07.11.2023